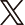生成AIボイスチェンジャーで、音声の可能性が爆上がり!
前回のブログでは、AIで音楽のボーカルや楽器の音を分離する「音源分離技術」を紹介しましたが、今回はさらに進化した「音響生成AI」に注目してみました。最近話題の生成AIを使って、どんなことができるのか見ていきましょう!
音響生成技術って何?
簡単に言うと、AIが人の声を学習して、新しい声を作り出す技術のことです。「ボイスチェンジャーのすごいやつ」って思ってもらえればOK!

例えば、自分の声をAIに覚えさせて、誰か他の人の話し方や歌い方を自分の声で再現できちゃう。しかも、英語でもフランス語でも、言語を問わず自分の声で作れるってすごくないですか?
ゼロショット音声生成を叶える「Seed-VC」
今回試してみたのは「Seed-VC(Seed Voice Conversion)」という音響生成AIツール。このツールがすごいのは、トレーニングが一切いらないところ。1~30秒くらいの音声サンプルさえあれば、どんな声でもクローンできちゃうんです!
特長をざっくりまとめると:
- 特定の声をもとに別の声を作れる
- 歌声や話し方のテンポ、トーンを自由に調整
- カスタムデータを使った学習も可能
https://github.com/Plachtaa/seed-v
自前のPCでSeed-VCを試してみた!
MacBook Air(M3チップ搭載)を使ってSeed-VCを動かしてみました。
Seed-VCの動作環境は、WindowsやLinux推奨なためGPUの指定がNVIDIAのDUDAになっています。MacのApple Siliconで動作させるには、Pytorchの設定を”mps”に変更する必要があります。ポイントはここ:seed-vc/app.py
# 修正前
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 修正後
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")修正して試してみたところ、生成AIがApple Siliconで高速動作しているのを確認できたが、処理中に演算のエラーが発生。
PyTorchのissueスレッドを確認するとMac版の既知の問題のようですが、このブログ公開時では修正版は出ていないようなので、実際に試すときはPyTorchの最新情報をチェックしてほしい。
https://github.com/Plachtaa/seed-v
AIが作った音声、実際に聞いてみた!
Seed-VCは、GUI版、リアルタイムGUI版、コマンドライン版などが用意されており、AIボイスチェンジャーみたいに、リアルタイム処理で試したかったが、Apple Siliconによる生成処理が必須なので、残念ながら今回はWebUI版を使ってみることに。
ターミナルで app.py を起動後に、ブラウザで http://127.0.0.1:7860/ にアクセスすると以下のようなUI画面が表示される、ブラウザで操作できるのでめっちゃ簡単!
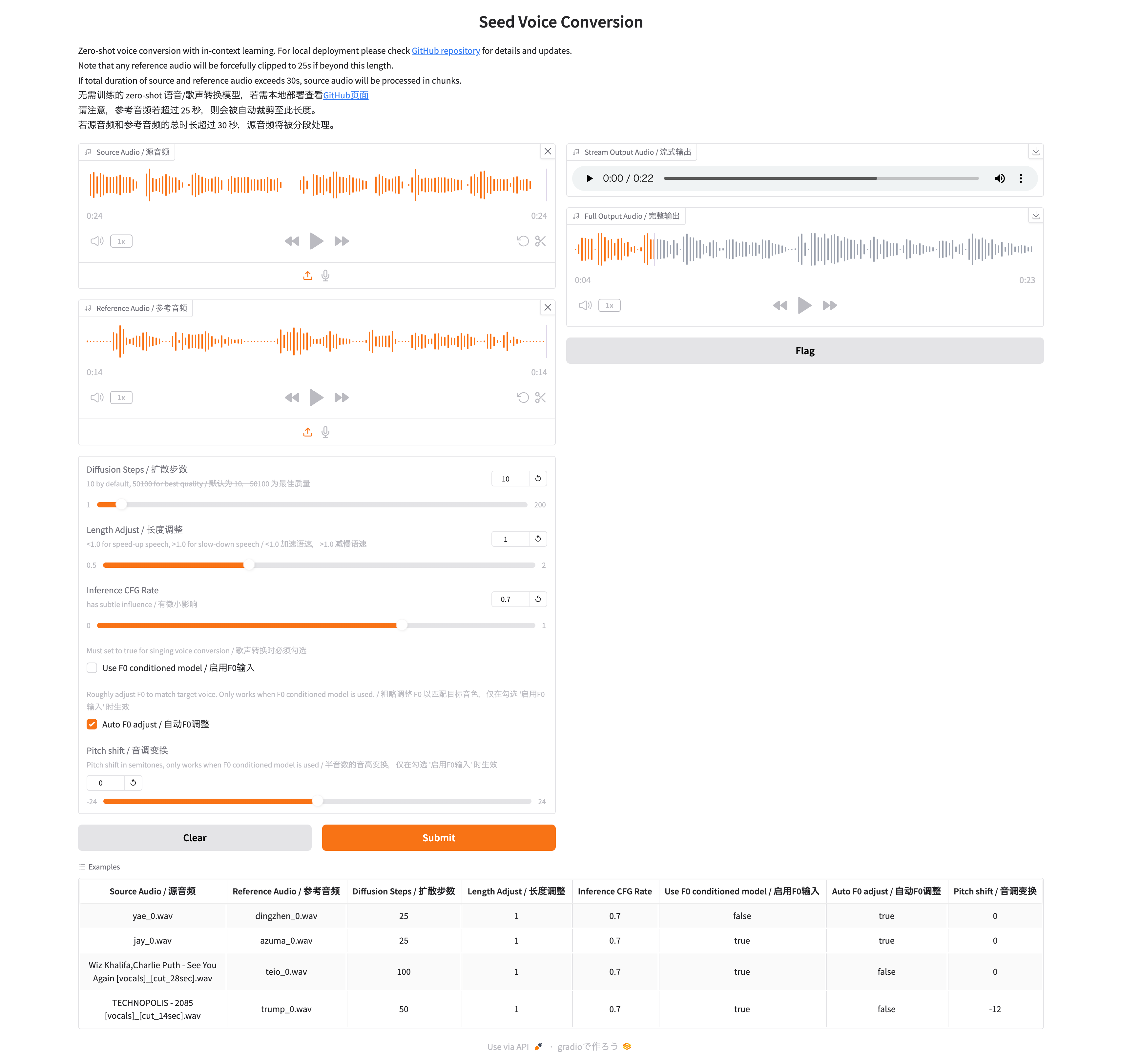
前段でも説明した通り、学習用データと変換元データを元にして、出力データを生成することができる。
各種パラメータで、出力データの推論のステップ数、音声のスピード、歌声変換の有無などの設定ができるので、イメージに合った音声に微調整することができるようになっている。
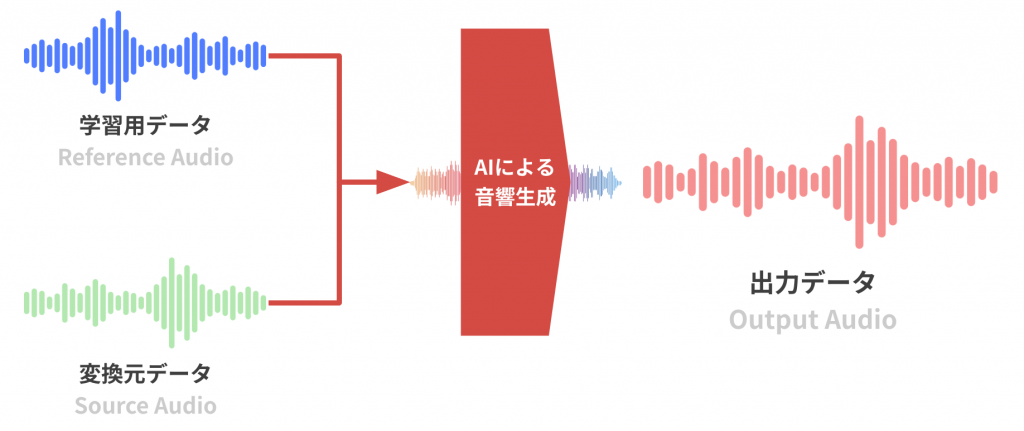
まず、自分の声を録音して、学習用データを用意することに
学習用データ:私の声サンプル
学習データは、このブログの紹介を14秒ぐらい喋ってみた。
変換元データは、音読さんという音声読み上げソフトのオンラインツールを使用して、時事ネタのニュース音声を作成。
変換元データ:ニュース音声(日本語)©音読さん
学習用、変換元のデータが揃ったので、Seed-VCで変換元データのニュース音声を私の声で生成!!
出力データ:ニュース音声(日本語)Seed-VCの生成データ
生成された音声を聞いてみると・・・もう感動モノ!!本人はこんなに滑舌良くない(笑)
「これ本当に自分の声?」ってくらい自然な仕上がりになった。
続いて英語・フランス語のニュース音声に挑戦!
変換元データ:ニュース音声(英語)©音読さん
出力データ:ニュース音声(英語)seed-VCの生成データ
変換元データ:ニュース音声(フランス語)©音読さん
出力データ:ニュース音声(フランス語)Seed-VCの生成データ
これだけ英語やフランス語を自分の声で流暢!?に喋ってくれるなら、会話の翻訳などで活用できるのではないかと思う。
音響生成AIのこんな使い方もあり!
この技術、いろんなシーンで役立ちそうです。例えば:
- 多言語のリアルタイム翻訳サービス
自分の声で他言語を話しているように音声を生成できる機能を活用して、リアルタイム翻訳アプリを開発。
会議中に話した日本語を英語やフランス語にリアルタイム変換し、現地の話者とスムーズにコミュニケーション。 - 電話応答サービス
自分の声で留守電や電話の自動応答をしてくれるサービス
電話に出れない時に一時受けを気付かれることなくできる、また高齢者の詐欺電話の対策に活用 - カスタム音声のコールセンター応答
企業が特定のブランドイメージに合わせたカスタム音声を作成可能に。
カスタマイズされた優しい声や落ち着いたトーンで顧客応答を行うAIカスタマーサポート。 - エンタメ向けのカラオケシミュレーション
カラオケで、自分の声をプロの歌手のように調整したり、別の声質でシミュレーション可能。
自分の歌声を有名な歌手のように変換し、新しい歌い方を体験できる。 - ゲームやメタバースでの音声アバター
オンラインゲームやメタバースで、自分の声をキャラクターに合わせた声に変換。
RPGのキャラクターに低い声やエコーのかかった声を設定して没入感を向上。 - 発声障がい者支援アプリ
声を失った人や発声が難しい人が、少量の録音データをもとに自分の声に近い音声で会話できるツールを提供。
スマートフォンを通じて、個人の声を生成し、自然なコミュニケーションを可能に。
今回ご紹介したの音響生成AIは、音声以外の様々な環境音の生成に進化する可能性もある。興味がある方は、ぜひ一度触ってみてほしい!
おまけ
先日発表された話題の「DeepSeek-R1」ですが、注目すべき点は、AI学習においてショートカットのような手法を見つけたことです。これにより、高性能なNVIDIAのGPUを使わなくても、短期間でAI学習を進めることが可能になるようです。この技術によってAI開発のコストが大幅に削減され、AI業界にとって大きな転機となるかもしれません。
次回の「DiXiM Style」Tech版では、最新のLLMなどについても詳しく解説していきたいと思いますので、ぜひご期待ください。
Hiroshi Abe
Published on Jan, 2025